AI Inference on the AIR-T with TensorRT¶
The goal of this tutorial is to demonstrate execution of a neural network inference engine on the AIR-T by using the AIR-T to receive a signal, preprocess the associated signal samples, perform the neural network inference, and compare the results to expected calculations. This tutorial will not cover the training of a neural network. Instead, it provides an example neural network with static, pre-defined, weights that calculates the average power of a batch of complex-valued signal samples.
This tutorial applies to AirStack v2.2+. For AirStack v2.1 and v2.0, follow the upgrade instructions here. For older versions of AirStack (v1.x and earlier), please see these instructions.
Background¶
For this tutorial, we will use the inference tools in our open source airstack-examples library, which provides a working example of how to perform neural network inference on the AIR-T. In this tutorial, we demonstrate a simple neural network model with a single output node that calculates the average of the instantaneous signal power across batches of signal samples received by the AIR-T's analog input. The source of the signal is at the discretion of the user: it can be a specific signal source, such as that from a signal generator, or merely the unconnected analog input to the AIR-T's transceiver.
The figure below shows the calculations for computing the average power of a set of signal samples:
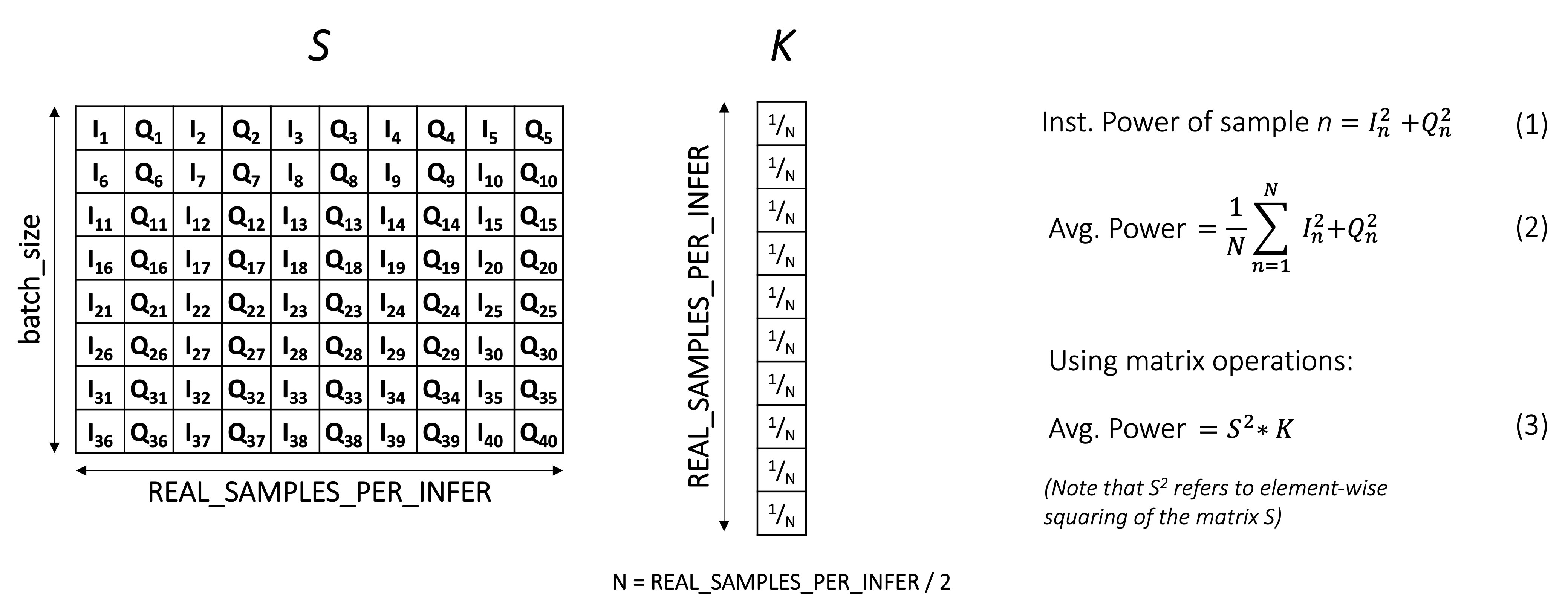
In this figure, the buffer size is 40 complex valued samples (80 real samples), with In representing the in-phase (real) component and Qn representing the quadrature ( imaginary) component of each sample. A common method to calculate the average power of the samples in this buffer is to compute the instantaneous power for each sample as the sum of I n2 + Qn2 as shown as Equation (1) and to then calculate the average of these values across the buffer using Equation (2).
An alternative method to calculating the power is to formulate the problem as a set of matrix operations. The 40-complex element buffer (again, 80 real samples) may be restructured into an 8 x 10 matrix of real samples, represented by S in the figure. If we then define a 10-element vector, K, such that each element has the value 1/N, then the matrix operations shown in Equation (3) are mathematically equivalent to Equation (2). Said differently, the average power of each row in S is computed by the matrix multiplication. This set of operations is also equivalent to a fully-connected neural network layer without a bias operation and represents a simple neural network that will be used in the following steps to demonstrate how to perform inference on the AIR-T.
Creating the Neural Network¶
The airstack-examples toolbox demonstrates how to create a simple neural network for TensorFlow, PyTorch, and MATLAB on a host computer. Installation of these packages for training is made easy by the use of Conda environment management tools (Anaconda). The output of each of these frameworks is a model file in an ONNX format, an open standard for representing machine learning models. Generally speaking, the AIR-T supports inference on any model that uses the ONNX format.
The Python code to create this neural network is provided for PyTorch, TensorFlow, and MATLAB:
- PyTorch:
airstack-examples/inference/pytorch/make_avg_pow_net.py - TensorFlow:
airstack-examples/inference/tensorflow/make_avg_pow_net.py - MATLAB:
airstack-examples/inference/matlab/make_avg_pow_net.m
When run, each of these functions will output a file called avg_pow_net.onnx. For convenience, we will use the airstack-examples/inference/pytorch/make_avg_pow_net.py file for this tutorial.
Creating the Inference Conda Environment¶
The first step is to create and activate a Conda environment in which to perform inference. This environment can be defined using the YAML file that is found in airstack-examples. This environment file does not include TensorRT which is required to run this example.
To install TensorRT you will first need to download the 10.3.0 TensorRT release from NVIDIA and extract the contents found here. Extract the contents of the 'python' folder from this file on your radio to /opt/conda-wheels/ (you will need to create this directory). Once you have downloaded and extracted the files, Deepwave provides a script that can be run to create your conda environment, install and configure TensorRT. To use the Deepwave provided TensorRT install script, from a terminal on your AIR-T, type the following commands:
- Create the
airstack-inferconda environment:
cd ~/conda/environments; ./conda_tensorrt_setup.sh airstack-infer.yml
This step may take up to 10 minutes.
- Activate the conda environment:
conda activate airstack-infer
If you do not want to use the provided TensorRT install script you will need to run the following commands to install TensorRT in the inference conda environment. Note we choose the appropriate TensorRT whl file that matches the python version specified in the conda environment.
-
Create and activate the conda build environment (note that the build environment only needs to be created once somewhere on the system):
conda create -n build conda mamba conda activate build -
Create and activate the conda environment:
conda env create --solver=libmamba -f airstack-infer.yml conda activate airstack-infer - Install and configure TensorRT:
pip install /opt/conda-wheels/TensorRT-10.3.0.26/python/tensorrt-10.3.0-cp310-none-linux_aarch64.whl patchelf --set-rpath '$ORIGIN/../../..' "$CONDA_PREFIX/lib/python3.10/site-packages/tensorrt/tensorrt.so"
Performing Model Optimization with TensorRT¶
We will optimize the network in avg_pow_net.onnx using NVIDIA's TensorRT. This step may be done by running the onnx2plan.py program found in the airstack-examples repository,
cd ~/inference; python onnx2plan.py
which will produce a PLAN file in the same folder as that of the ONNX file; by default this file will be pytorch/avg_pow_net.plan. The .plan file is an optimized version of the neural network that will be used for inference in the next steps.
TensorRT Optimization Application Note - When training a neural network for execution on the AIR-T, make sure that the layers being used are supported by your version of TensorRT. To determine what version of TensorRT is installed on your AIR-T, open a terminal and run:
$ dpkg -l | grep TensorRT
The supported layers for your version of TensorRT may be found in the TensorRT SDK Documentation under the TensorRT Support Matrix section.
Understanding the Inference Code¶
The inference code itself is contained in the file run_airt_inference.py, which first defines the top-level inference settings for the neural network and radio as shown in the excerpt below. Note that these settings are correct for the neural network used in this tutorial but, in general, will depend on the structure of the model.
import numpy as np
import trt_utils
from SoapySDR import Device, SOAPY_SDR_RX, SOAPY_SDR_CF32, SOAPY_SDR_OVERFLOW
# Top-level inference settings.
CPLX_SAMPLES_PER_INFER = 2048 # Half input_len from the neural network
PLAN_FILE_NAME = 'pytorch/avg_pow_net.plan' # File created from uff2plan.py
BATCH_SIZE = 128 # Less than or equal to max_batch_size from uff2plan.py
NUM_BATCHES = 16 # Batches to run. Use float('Inf') to run continuously
# Top-level SDR settings.
SAMPLE_RATE = 7.8125e6 # AIR-T sample rate
CENTER_FREQ = 2400e6 # AIR-T Receiver center frequency
CHANNEL = 0 # AIR-T receiver channel
As a side note, the trt_utils import is a provided utility to manage the device mapped memory that enables the AIR-T's zero-copy feature.
Inference Loop¶
The code below will perform the following operations:
- Allocate a shared memory buffer on the AIR-T using pyCUDA
- Initialize the neural network using TensorRT
- Initialize and set up the AIR-T Radio
- Receive samples for a fixed number of batches in a while loop to:
- Read data into the buffer from the RF front end
- Test to ensure that the data was received properly
- Feed the data buffer into the neural network for inference
- Test if the neural network computation matches what is expected.
Here is the source code for the inference loop:
def main():
# Allocate a shared memory buffer on the AIR-T using pyCUDA
trt_utils.make_cuda_context()
samples_per_read = CPLX_SAMPLES_PER_INFER * BATCH_SIZE
buff_len = 2 * samples_per_read
sample_buffer = trt_utils.MappedBuffer(buff_len, np.float32)
# Initialize the neural network using TensorRT
dnn = trt_utils.TrtInferFromPlan(PLAN_FILE_NAME, BATCH_SIZE, sample_buffer)
# Initialize and setup the AIR-T Radio
sdr = Device()
sdr.setGainMode(SOAPY_SDR_RX, CHANNEL, True)
sdr.setSampleRate(SOAPY_SDR_RX, CHANNEL, SAMPLE_RATE)
sdr.setFrequency(SOAPY_SDR_RX, CHANNEL, CENTER_FREQ)
rx_stream = sdr.setupStream(SOAPY_SDR_RX, SOAPY_SDR_CF32, [CHANNEL])
sdr.activateStream(rx_stream)
# Receive samples for a fixed number of batches in a while loop
print('Receiving Data')
ctr = 0
while ctr < NUM_BATCHES:
try:
# Read data in to the buffer from the RF front end
sr = sdr.readStream(rx_stream, [sample_buffer.host], samples_per_read)
# Test to ensure that the data was received properly
if sr.ret == SOAPY_SDR_OVERFLOW:
print('O', end='', flush=True)
continue
# Feed the data buffer into the neural network for inference
dnn.feed_forward()
# Test if the neural network computation matches what is expected.
output_arr = dnn.output_buff.host
if not passed_test(sample_buffer.host, output_arr):
raise ValueError('Neural network output does not match numpy')
except KeyboardInterrupt:
break
ctr += 1
sdr.closeStream(rx_stream)
if ctr == NUM_BATCHES:
print('SUCCESS! All inference output values matched expected values!')
The code will print out a message indicating whether execution was successful.
Result Validation¶
To test that the computation from Equation (3) matches that of Equation (2) we will create a function (shown below) that uses NumPy to calculate Equation (2) and that compares the result to the neural network computation.
def passed_test(buff_arr, result):
""" Make sure numpy calculation matches TensorFlow calculation. Returns True
if the numpy calculation matches the TensorFlow calculation"""
buff = buff_arr.reshape(BATCH_SIZE, -1) # Reshape so 1st dim is batch_size
sig = buff[:, ::2] + 1j * buff[:, 1::2] # Convert to complex valued array
wlen = float(sig.shape[1]) # Normalization factor
np_result = np.sum((sig.real ** 2) + (sig.imag ** 2), axis=1) / wlen
return np.allclose(np_result, result)
Running the Example Code¶
First, make sure that you have:
- Enabled the airstack Conda environment that was created in a previous step
- Optimized the model to create the
pytorch/avg_pow_net.planfile
To perform inference using that plan file, run the following:
cd ~/inference; python run_airt_inference.py
You should see the following output:
(airstack-infer) $ cd ~/inference; python run_airt_inference.py
[TRT] [I] Loaded engine size: 0 MiB
[TRT] [V] Deserialization required 1305 microseconds.
Input layer 'input_buffer': min/max shape (1, 4096), (128, 4096)
[TRT] [V] Total per-runner device persistent memory is 0
[TRT] [V] Total per-runner host persistent memory is 32
[TRT] [V] Allocated device scratch memory of size 2114560
[TRT] [V] - Runner scratch: 2114560 bytes
[TRT] [I] [MemUsageChange] TensorRT-managed allocation in IExecutionContext creation: CPU +0, GPU +2, now: CPU 0, GPU 2 (MiB)
[TRT] [V] CUDA lazy loading is enabled.
TensorRT Inference Settings:
Batch Size : 128
Explicit Batch : True
Input Layer
Name : input_buffer
Shape : (128, 4096)
dtype : float32
Output Layer
Name : output_buffer
Shape : (128, 1)
dtype : float32
Receiver Output Size : 524,288 samples
TensorRT Input Size : 524,288 samples
TensorRT Output Size : 128 samples
[INFO] Device master clock rate: 125.000 MHz (unchanged)
[INFO] Starting radio stream initialization
[INFO] Performing transceiver initial calibration
[INFO] Radio stream initialization complete
Receiving Data
Status of inference operation: success = True
Status of inference operation: success = True
Status of inference operation: success = True
Status of inference operation: success = True
Status of inference operation: success = True
Status of inference operation: success = True
Status of inference operation: success = True
Status of inference operation: success = True
Status of inference operation: success = True
Status of inference operation: success = True
Status of inference operation: success = True
Status of inference operation: success = True
Status of inference operation: success = True
Status of inference operation: success = True
Status of inference operation: success = True
Status of inference operation: success = True
SUCCESS! All inference output values matched expected values!
If you see the message at the end saying "SUCCESS! All inference output values matched expected values!" then you successfully executed the DNN.
Next Steps¶
The goal of this tutorial was to demonstrate the step-by-step process to perform neural network inference. The airstack-examples repo provides all of the source code necessary to properly allocate shared memory buffers (using pyCUDA) and feed signal data from the AIR-T's radio to a neural network for inference.
We encourage users to apply the lessons learned in this tutorial to use the AIR-T to create their own neural network for inference.